0. AI / ML / DL / GenAI
AI, ML, DL, GenAI는 서로 다른 기술이 아니라 포함 관계다. AI가 가장 넓고, 그 안에 ML, ML 안에 DL이 있다. GenAI는 그중 "새 결과물을 만드는" 쪽이다.
- AI(Artificial Intelligence, 인공지능): 사람의 지능이 필요해 보이는 일을 처리하는 시스템 전체. if-else(조건에 따라 동작을 나누는 규칙문)로 규칙을 직접 짠 프로그램도 AI다.
- ML(Machine Learning, 머신러닝): 규칙을 사람이 적지 않고 데이터에서 패턴을 스스로 찾게 하는 방식. "고양이는 이렇게 생겼다"를 코드로 쓰는 대신, 고양이 사진 수만 장을 보여 주고 모델(입력을 받아 예측·생성을 하는 계산 규칙)이 특징을 찾게 한다.
- DL(Deep Learning, 딥러닝): ML을 신경망(숫자를 여러 단계로 변환하며 패턴을 학습하는 모델) 여러 층으로 깊게 쌓은 것. 층이 깊을수록 더 추상적인 특징을 잡는다.
- GenAI(Generative AI, 생성형 AI): 학습한 패턴으로 글·그림·코드 같은 새 결과물을 만드는 AI. 챗봇과 이미지 생성기가 여기 속한다.
앞의 셋은 주로 "알아보고 분류·예측"하는 쪽이고, GenAI는 "새로 만든다"는 점이 다르다.
딥러닝 대표 구조 둘 — CNN과 RNN

CNN(Convolutional Neural Network, 합성곱 신경망)은 이미지에서 가까운 픽셀(이미지를 이루는 작은 점) 묶음의 특징을 단계적으로 찾는다. 필터(작은 영역을 훑으며 특징 점수를 내는 창)로 이미지를 조금씩 옮겨 가며 살핀다. 낮은 층은 선·모서리 같은 단순한 특징을, 높은 층은 귀·꼬리 같은 큰 형태를 잡는다. 얼굴 인식, 의료 영상 판독, 자율주행 표지판 인식이 CNN 계열이다.
RNN(Recurrent Neural Network, 순환 신경망)은 순서가 있는 데이터를 앞에서부터 하나씩 처리한다. 단어를 차례로 읽으며 내부 상태(지금까지 읽은 정보를 담은 값)를 갱신하고, 그 상태로 다음 단어를 예측한다. "나는 밥을 ___" 다음을 맞히려면 앞 단어 정보가 필요하다. 이전 계산 결과가 다음 계산에 다시 들어가서(recurrent) "순환"이다. 번역·음성 인식·자동완성에 쓰였다.
RNN의 약점은 긴 문장에서 앞쪽 정보가 뒤까지 잘 전달되지 않는다는 점이다. 이 문제를 줄인 Transformer(트랜스포머, 문장 안 단어들의 관계를 한 번에 계산하는 신경망 구조)가 나오면서 번역·챗봇의 주류가 됐고, 오늘날 GenAI 대부분이 Transformer 기반이다.
1. RNN의 한계. 왜 Transformer가 나왔나

RNN의 핵심 한계는 긴 문맥과 속도다. RNN은 단어를 하나씩 순서대로 읽으며 내부 상태를 갱신하고, 그 상태로 다음 단어를 예측한다. 여기서 두 문제가 생긴다.
- 앞 정보가 흐려진다: 긴 문장에서 시작 부분의 단서가 뒤로 갈수록 약해진다(장거리 의존성 — 멀리 떨어진 단어 사이의 관계에 약함).
- 느리다: 단어를 순서대로 처리해야 해서 병렬화(여러 계산을 동시에 실행하는 것)가 어렵다.
LSTM과 GRU는 이 한계를 줄이려고 나온 RNN 개선형이다. 둘 다 게이트(정보를 얼마나 기억·삭제·출력할지 정하는 계산 장치)를 단다.
- LSTM(Long Short-Term Memory, 장단기 기억): 장기 기억 라인인 cell state(정보를 오래 보관하는 내부 값)를 따로 두고 게이트 3개로 관리한다. RNN보다 긴 문맥을 잘 잡는다.
- GRU(Gated Recurrent Unit): LSTM의 경량 버전. 게이트를 2개로 줄여 더 가볍고 빠르며, 성능은 LSTM과 비슷한 경우가 많다.
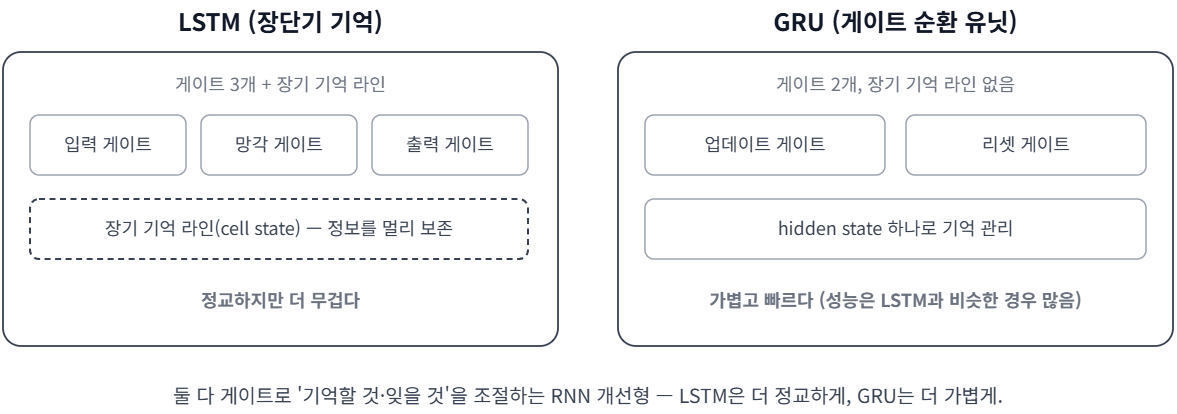
하지만 LSTM·GRU도 순차 처리라 병렬이 어렵고, 아주 긴 문맥엔 한계가 남는다. 결국 문장 전체를 한 번에 보는 방법이 필요해졌다.
2. Transformer의 핵심 3가지 (2017, "Attention is All You Need")
Transformer의 핵심은 문장 전체를 한 번에 비교한다는 점이다. 세 가지 장점으로 빠르게 주류가 됐다.
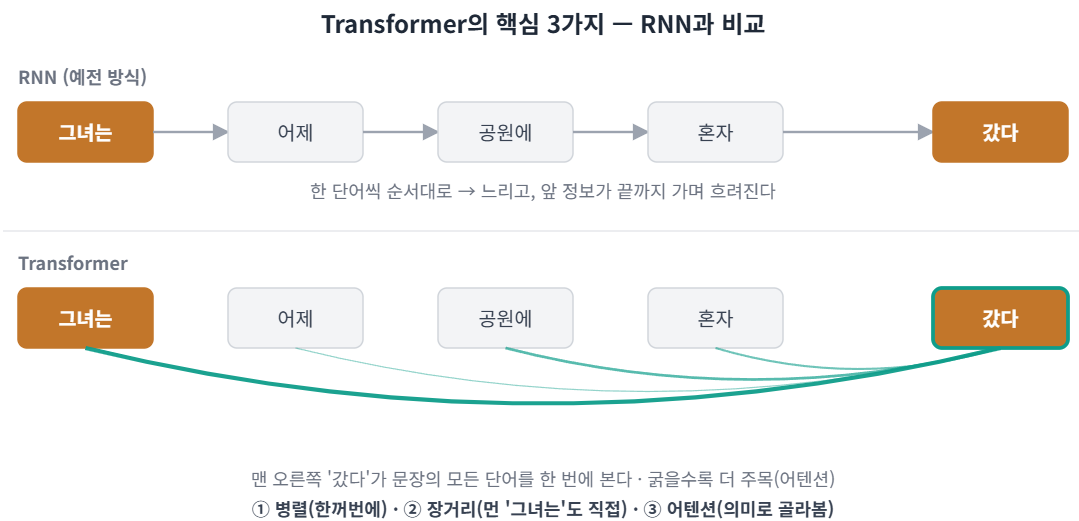
- 병렬 처리: 모든 토큰(문장을 잘게 나눈 조각, 자세히는 3장)을 한꺼번에 계산한다. GPU(같은 계산을 동시에 대량으로 처리하는 칩)와 잘 맞아 학습이 빠르다.
- 장거리 의존성: 멀리 떨어진 단어도 행렬곱(숫자 표 두 개를 곱해 한 번에 모든 단어 쌍의 점수를 내는 계산) 한 번으로 바로 비교한다.
- 어텐션(attention, 관련 있는 단어에 더 큰 비중을 주는 계산): 어떤 단어가 어떤 단어를 봐야 하는지 학습한다. 옆 단어가 아니라 의미적으로 관련된 단어를 본다.
3. 문장이 숫자가 되기까지
모델은 숫자만 계산한다. 그래서 입력 문장은 세 단계를 거쳐 숫자가 된다.
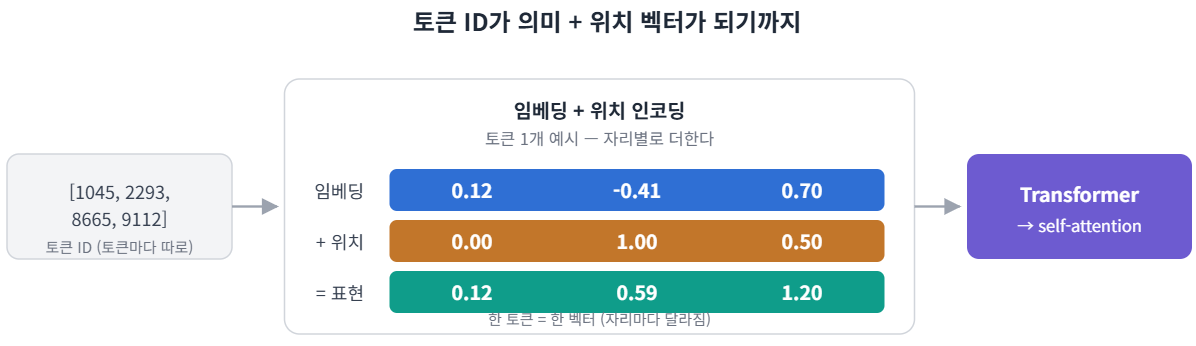
1. 토큰화(tokenization) — 문장을 토큰으로 쪼개고 각 토큰에 정수 ID(식별 번호)를 붙인다. 한 단어가 여러 토큰으로 쪼개질 수 있는데, 이 조각을 부분단어(subword)라고 한다. 그래서 단어 수와 토큰 수가 다를 수 있다. 학습 때 쓴 토크나이저(토큰화 규칙·프로그램)를 추론(학습된 모델로 답을 계산하는 단계) 때도 그대로 써야 한다.

2. 임베딩(embedding) — ID는 의미 없는 번호일 뿐이다. 임베딩은 그 ID를 의미가 담긴 벡터(숫자 여러 개를 한 줄로 묶은 값)로 바꾼다. 번호를 넣으면 정해진 값을 꺼내 주는 표(lookup table)처럼 동작한다. 의미가 비슷한 토큰은 가까운 벡터가 되도록 학습된다. 예를 들어 king 근처에 queen, Paris 근처에 Tokyo가 놓인다 — 벡터 사이 거리가 곧 의미의 거리다.
3. 위치 인코딩(positional encoding) — 문장을 한꺼번에 계산하면 순서 정보가 사라진다. 그러면 "개가 사람을 물었다"와 "사람이 개를 물었다"를 같은 문장으로 본다. 그래서 위치를 나타내는 벡터를 임베딩에 더해 순서를 심는다.
토크나이저는 모델 학습 때 고정된다. 보통 여러 세대 모델이 같은 토크나이저를 공유한다(예: GPT-4o~GPT-5.1은 o200k_base를 쓴다). 토큰 사전을 새로 설계할 때만 바뀌며, cl100k_base→o200k_base가 그런 경우다.
4. Self-Attention. 모든 단어 쌍에 가중치
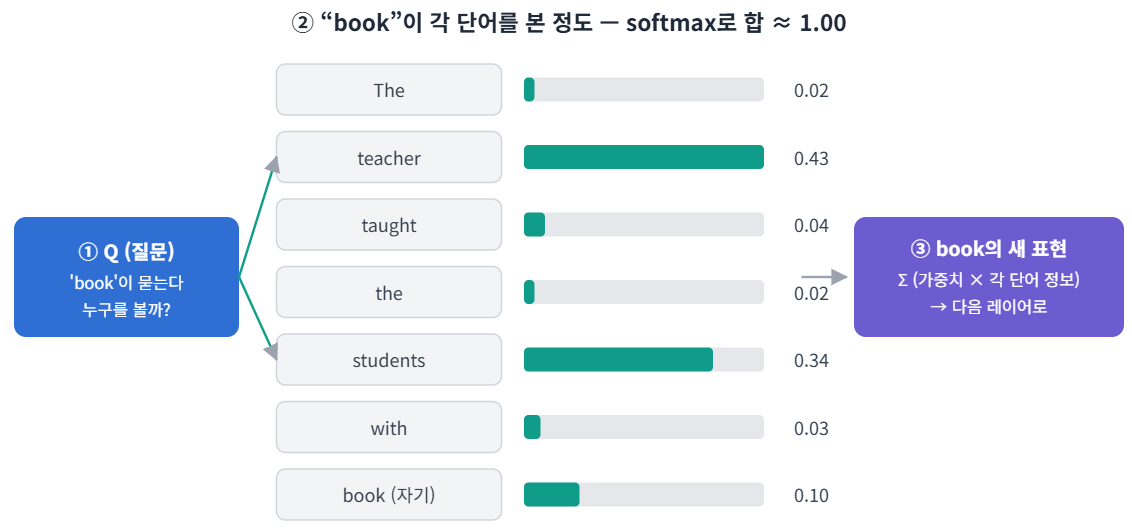
Self-Attention(한 문장 안 토큰끼리 서로의 중요도를 계산하는 방식)의 핵심은 모든 토큰 쌍의 관계를 한 번에 계산한다는 점이다. 각 토큰은 문장 안 모든 토큰에 중요도 점수를 매기고, 그 점수에 비례해 다른 토큰의 정보를 받아온다. N개 토큰이면 N×N 쌍을 한 번에 비교한다. 그래서 직전 단어가 아니라 어떤 단어든 같은 계산 단계에서 볼 수 있다.
예) "The teacher taught the students with the book."
book→teacher에 높은 가중치 (책을 든 사람이 teacher일 수 있음)book→students에도 높은 가중치 (책을 가진 사람이 students일 수 있음)the·with같은 기능어 → 낮은 가중치
이때 단어들에 매겨진 날점수(확률로 바꾸기 전 점수)를 합이 1인 가중치(다른 토큰 정보를 얼마나 반영할지 나타내는 숫자)로 바꿔 주는 함수가 softmax(여러 점수를 합이 1인 값으로 바꾸는 함수)다. 그래서 한 단어가 다른 단어들을 본 가중치는 모두 더하면 1이 된다. 이 softmax가 출력층의 softmax와 어떻게 다른지는 뒤에서 다룬다.

이 가중치는 학습으로 자동 결정되고, 어텐션 맵(토큰 쌍의 가중치를 표·그림으로 나타낸 것)으로 어떤 토큰이 어떤 토큰을 크게 보는지 확인할 수 있다.
위 설명은 문장을 양방향으로 다 보는 인코더(입력 문장을 통째로 읽어 표현을 만드는 쪽)에 해당한다. ChatGPT 같은 디코더(왼쪽부터 토큰을 하나씩 만들어 내는 쪽) 모델은 다음 단어를 순서대로 생성하므로 미래 단어를 미리 보면 안 된다. 그래서 뒤를 가리는 Masked Self-Attention(미래 토큰을 보지 못하게 막은 self-attention)을 쓴다.
5. Multi-Head.
Multi-Head Attention(여러 어텐션 계산을 병렬로 돌리는 방식)의 핵심은 관계를 여러 관점으로 나누어 본다는 점이다.

각 계산 세트를 헤드(독립적으로 어텐션을 계산하는 부분)라고 한다. 같은 문장에도 관계는 여러 종류다. 어떤 헤드는 주어-동사 관계를, 어떤 헤드는 지시어가 가리키는 대상을 크게 본다. 헤드별 역할은 사람이 정해 주지 않고 학습 과정에서 자동으로 나뉜다.
6. FFN + Softmax. 어휘 전체의 확률표
self-attention은 Transformer 계산 단위의 절반이다. 나머지 핵심은 FFN(Feed-Forward Network, 피드포워드 네트워크)과 출력층 softmax다. 여기서는 두 가지를 본다. (6-1) 블록이 어떻게 생겼고 왜 여러 번 반복되는지, (6-2) 마지막 결과가 어떻게 다음 단어 확률로 바뀌는지.
6-1. 블록 안. self-attention + FFN, 그리고 ×N층
한 블록(같은 계산 묶음을 반복하는 단위)은 self-attention과 FFN 두 단계로 이뤄진다. 역할은 이렇게 나뉜다.
- self-attention: 토큰끼리 정보를 주고받는다(섞는다). 관련 있는 토큰의 정보를 더 크게 섞는다.
- FFN: 각 토큰의 벡터를 따로 변환한다. 토큰끼리 섞지 않고, 같은 작은 신경망을 모든 토큰에 한 번씩 적용한다. 이 신경망으로는 MLP(Multi-Layer Perceptron, 입력을 몇 겹 곱하고 더해 변환하는 기본 신경망)를 주로 쓴다.
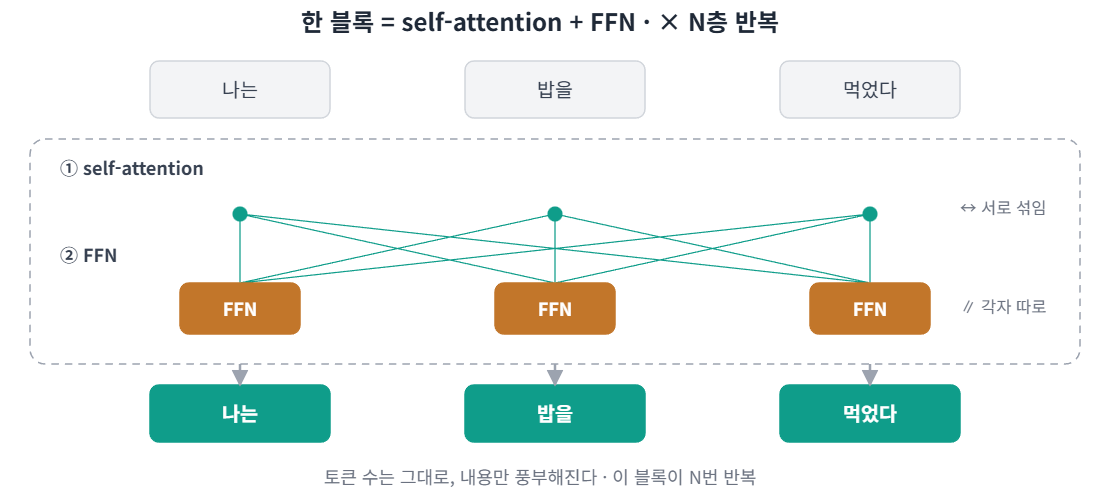
즉 self-attention은 토큰 간 교환, FFN은 토큰별 가공이다. 이 [self-attention + FFN] 한 세트가 블록이고, N층 반복된다. 토큰 개수는 그대로 유지되고, 층을 지날수록 각 토큰 벡터에 더 정교한 문맥이 쌓인다.
self-attention만 있으면 정보를 섞을 뿐 깊게 변환하지는 못한다. 섞은 정보를 실제 의미로 가공하는 계산은 FFN이 담당한다.
6-2. 출력층. 어휘 전체의 확률 분포
마지막 블록을 지나면 모델은 다음 토큰을 예측한다.

마지막 토큰의 벡터(앞 문맥 정보가 담겨 있다)를 꺼내, 사전의 모든 토큰과 비교해 점수를 매긴다. 점수표 길이는 사전 크기(보통 수만)와 같다. 이 점수 묶음을 logits(확률이 되기 전의 날 점수)라고 한다. 이 점수들은 확률이 아니라 다 더해도 1이 아니다. 여기에 softmax를 적용하면 각 점수가 0~1 사이가 되고 전체 합이 1인 확률 분포가 된다.
7. 확률표에서 실제로 한 단어 뽑기
지금까지가 한 번의 forward pass(순전파)다. 순전파는 입력에서 출력까지 한 방향으로 계산하는 과정이다(입력 → 함수 체인 → 출력).
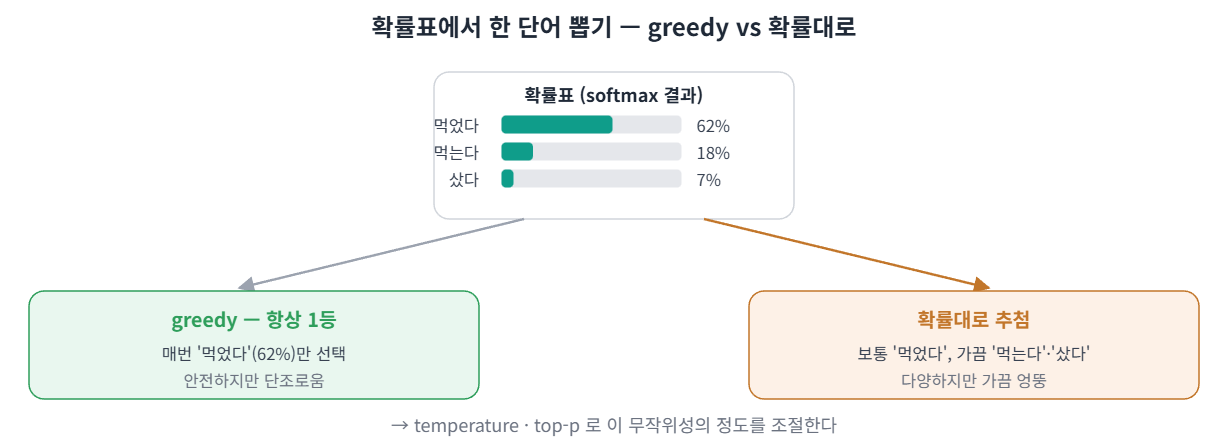
중요한 점은 모델 출력이 단어 하나가 아니라는 것이다. softmax를 통과한 결과는 사전의 모든 후보 단어에 확률이 퍼져 있는 표다(다 더하면 1). "나는 밥을 ___" 다음을 예측하면 대략 이렇게 나온다:
먹었다 0.62
먹는다 0.18
샀다 0.07
... (사전에 있는 수만 개 단어 전부)
─────────────
합계 1.0즉 모델은 정답 단어 하나를 선언하지 않는다. 각 단어가 다음에 올 가능성을 확률 분포로 건넬 뿐이다. 그래서 실제 한 단어를 정하려면 이 분포에서 하나를 고르는 과정이 필요하다. 이를 sampling(샘플링, 확률 분포에서 후보 하나를 고르는 것)이라 하고, 그래서 "뽑는다"고 말한다.
뽑는 방식은 양 극단으로 볼 수 있다.
- 항상 1등만 고르기(greedy, 매 단계 현재 1등만 고르는 방식): 안정적이지만 매번 비슷한 결과가 나온다.
- 확률대로 뽑기: 확률 낮은 후보도 가끔 나와 다양해지지만, 제한이 약하면 엉뚱한 결과가 나온다.
이 무작위성의 강도를 조절하는 설정이 추론 파라미터(답을 생성할 때 출력 방식을 조절하는 값)다. temperature(온도)는 분포를 평평하게(다양) ↔ 뾰족하게(보수적) 만들고, top-p는 뽑을 후보를 확률 상위 일부로 좁힌다.
8. 학습은 어떻게 이뤄지는지 순전파와 역전파로 알아보자
이미 다 배운 모델은 답을 계산하기만 하면 되기 때문에 직진만 한다. 챗GPT 같은 챗봇 모델을 우리가 사용할 때는 질문(입력)을 넣으면 모델을 거쳐 답변(예측)이 나온다.
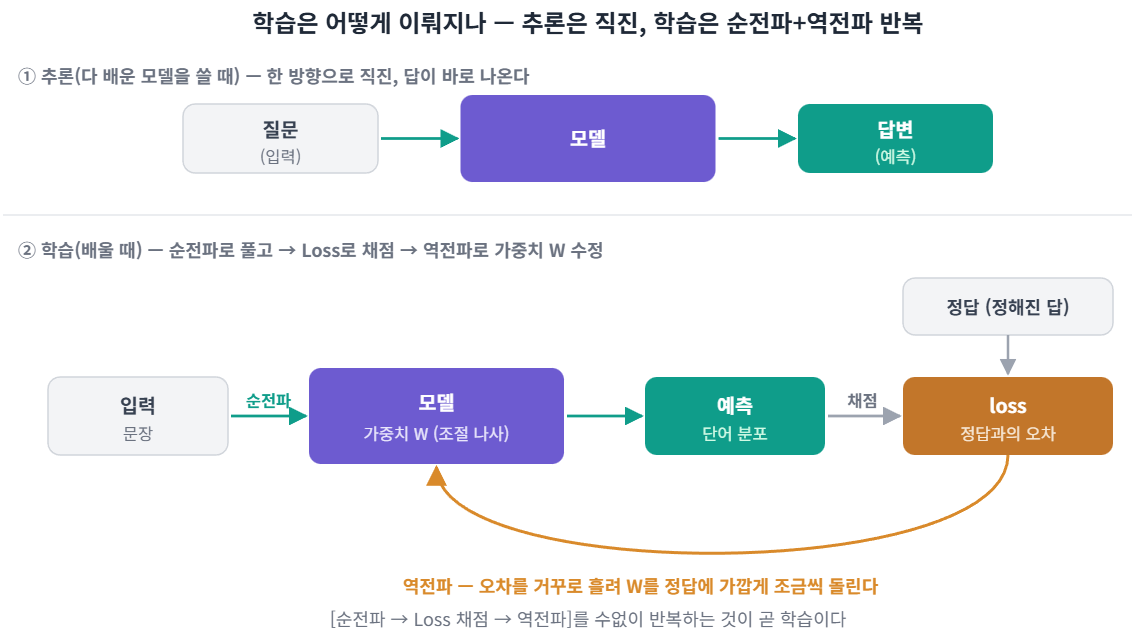
데이터로 모델 값을 조정하는 과정인 학습 때는 순전파로 예측을 낸 뒤, 정답과 얼마나 틀렸는지 loss(손실, 예측과 정답의 차이)를 구하고, 그 오차를 거꾸로 흘려보내며 가중치(모델이 학습으로 조정하는 숫자)를 고친다. 이 되돌아가는 과정이 역전파( backpropagation)다.
학습 때는 순전파와 역전파가 모두 필요하다
1. 순전파: 일단 문제를 푼다 (입력 → 모델 → 예측). Loss (채점): AI가 낸 '예측'과 실제 '정답'을 비교해서 "얼마나 틀렸나?" 오차를 채점한다
2. 역전파: 틀린 이유(오차)를 들고 거꾸로 되돌아간다. 그리고 모델 박스 안에 있는 '학습 가중치 W'(중요도를 결정하는 조절 나사)를 "다음엔 정답에 더 가깝게 나오도록" 조금씩 돌려가며 수정해서 다음엔 정답에 가깝도록 수정한다.
"순전파로 일단 예측 -> Loss 구함 -> 역전파로 가중치 수정" 이 단계를 계속 하는게 학습하는 과정이다.
9. 트랜스포머 파생 모델: 이해(BERT), 생성(GPT), 번역(T5)
마지막으로 곁가지 하나. 지금까지 본 '다음 단어 뽑기'는 디코더 구조 기준이었다. 원본 Transformer는 인코더와 디코더를 함께 썼는데, 두 부분을 따로 써도 된다는 게 알려지며 구조가 셋으로 갈렸다.
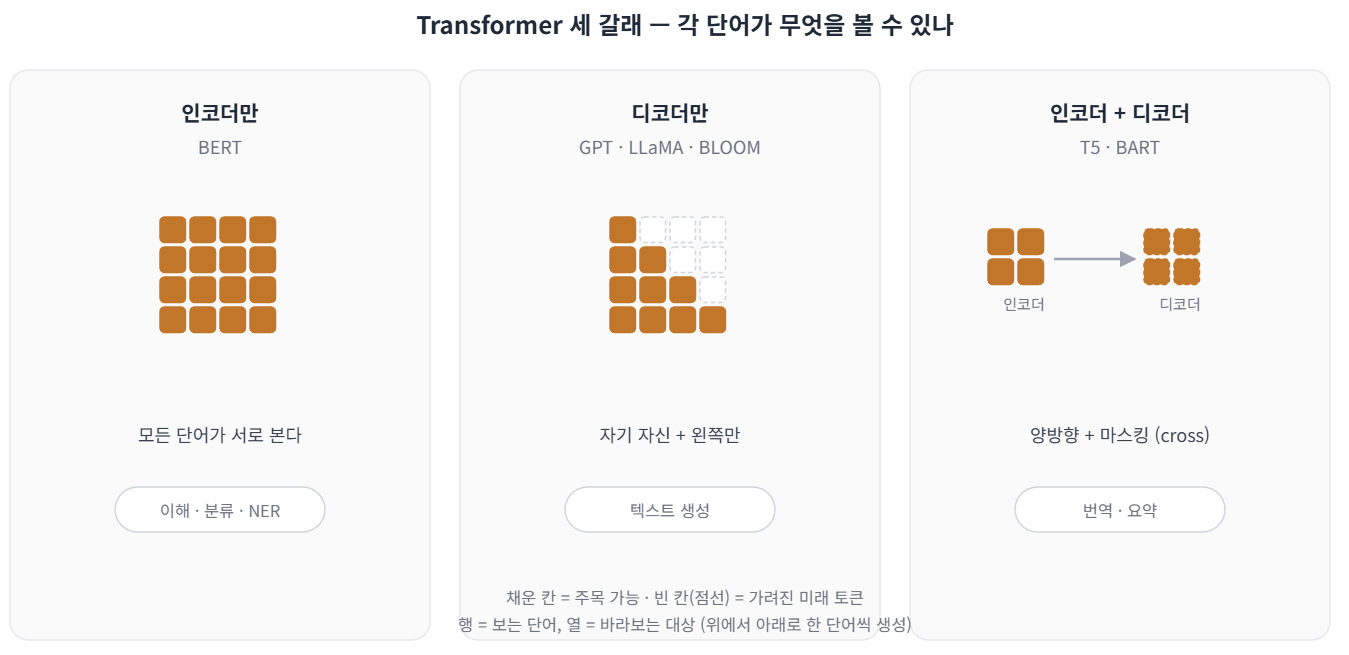
- 인코더+디코더 (T5, BART): 길이가 다른 입력→출력 작업에 강하다. 번역·요약이 대표적이다. (T5 = Text-to-Text Transfer Transformer)
- 인코더만 (BERT, Bidirectional Encoder Representations from Transformers): 양방향으로 전체를 읽어 분류·NER(개체명 인식 — 문장에서 사람·지명 같은 이름을 찾는 작업) 같은 이해형 작업에 강하다. 생성에는 부적합하다.
- 디코더만 (GPT, LLaMA): 왼→오로 다음 토큰을 예측한다. 현재 LLM(대규모 언어 모델)의 주류다. 여기서 self-attention은 마스킹된다 —
taught는 자기 자신과 왼쪽 단어만 보고, 뒤의students·book은 가려진다. 그래서 정답을 미리 보지 않고 "다음 단어"만으로 학습한다. (GPT = Generative Pre-trained Transformer)
참고
'> Tech' 카테고리의 다른 글
| LLM에게 일 시키는 법: 프롬프트와 추론 파라미터 [LLM 기본2] (0) | 2026.05.25 |
|---|---|
| MinIO 풀 확장 및 리밸런싱 (0) | 2025.09.19 |
| MinIO DirectPV PVC 테스트 (vagrant/k3s) (0) | 2025.09.18 |